Development You Stream, I Stream, We All Stream For Protocol Buffers
I’ve surprised the hell out of myself due to the fact that I haven’t yet written about my man-crush on Google’s Protocol Buffers (other than showing how to build a CI server for $5).
The summary is that I use Protocol Buffers to compact data into a binary encoding which is backwards and forwards compatible. I would call them a glorified set of binary key-value pairs. So, I get the speed and size benefits of binary code (as opposed to, say, JSON) - plus, I’m not locked into a specific schema (like if I were to store raw structs and arrays).
Google’s own documentation explains best their utility. Another good, brief take on JSON vs PBs is on StackOverflow.
Note: This post isn’t really a primer on using Protocol Buffers (as Google’s docs explain that very well), it’s about extending them to support streaming functionality.
Update: I have a follow-up post on an alternative way to stream Protocol Buffers as well.
Here Are Some Numbers
Just for some fun and anecdotal evidence, I took 10MB of uncompressed JSON (3 fields, 2 int32’s and 1 double) - and that exact data became approximately 2.8MB of uncompressed Protobuffers. It should be noted that Protobuffers, even with their built-in overhead, might still be smaller than the equivalent raw structures. The reason for this is that the Protobuf overhead comes from field tags, but the size reduction comes from using varints which take up only as much space as they need to (e.g. a raw int would be 4 bytes, but a pb-int might only be 1 or 2 bytes if that’s all that was needed).
Actually, looking at my example again, I think I went overkill on the ‘double’ datatype, as that’s a fixed 64-bits, and should have used a ‘float’ to save 32-bits per message!
My Protocol Buffer Use Cases
Anyways, at the end of the day, I’ve been using Protocol Buffers for a few years now - mostly for storing blobs and timeseries data, when a database doesn’t make sense (or, similarly, as an attachment in Couchbase Mobile). One other nifty use I’ve had for them is communicating between Android and C++.
Instead, I’ll just write my data to a pb file from Android, pull it back in on the C++ side and run my signal processing algorithms (or alternatively, I send an in-memory Protobuffer across the JNI boundary). This way, I can develop my C++ and Android code on their own, and have an interface layer which is robust to changes.
Protobuf (De)Limitations
There is a bit of functionality I’ve thought about, but never really needed - so never bothered writing any code for it. Until now.
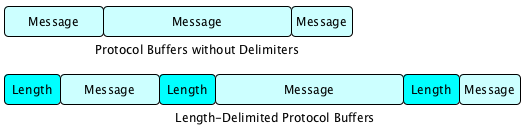
The Protobuffer docs mention the use case of streaming multiple messages, but that is not inherently supported because the Protocol Buffer message format is not self-delimiting. I always found this to be kinda stupid, as there are length delimiters INSIDE a Protocol Buffer message (e.g. strings are length-prefixed, embedded messages are length-prefixed, and repeated values are length-prefixed!).
It’s because of these examples that I didn’t really understand why Google didn’t throw in some sort of option for adding a self-delimiter to each message, with the explicit understanding that delimited blobs were not compatible with non-delimited blobs… I kind of get it, but at the same time, I kinda don’t.
In any case, I did it myself.
Streaming Python Messages
I read a great post by Eli Bendersky where he showed a simple example of how to do this delimiting in Python’s implementation of Protocol Buffers.
For context, here is my re-implementation of it (writes messages by appending to a file, reads in all messages from a file):
def to_hex(s):
lst = []
for ch in s:
hv = hex(ord(ch)).replace('0x', '')
if len(hv) == 1:
hv = '0'+hv
lst.append(hv)
return reduce(lambda x,y:x+y, lst)
def pack_message(message):
s = message.SerializeToString()
packed_len = struct.pack('<L', len(s))
return to_hex(packed_len + s)
def unpack_messages(buffer):
messages = []
n = 0
while n < len(buffer):
msg_len = struct.unpack('<L', buffer[n:n+4])[0]
n += 4
msg_buf = buffer[n:msg_len+n]
n += msg_len
message = sample_pb2.Sample()
message.ParseFromString(msg_buf)
messages.append(message)
return messages
with open('test.pbld', 'wb') as outfile:
for datum in data:
outfile.write(pack_message(datum))
with open('test.pbld', 'rb') as infile:
buffer = infile.read()
messages = unpack_messages(buffer)
In his original code, Eli writes to a socket - but the brass tacks are here. Note: I can’t recall if the to_hex was really necessary or not. I think I wrote it to make double-checking my work easier.
In summary, all we’re doing is first writing the size of the message in a little-endian encoded, fixed size (e.g. 4-byte int) and then writing the message out, and repeat. The length-delimiter must be a fixed-size, otherwise we wouldn’t know how to parse it, and we explicitly specify the endianness to avoid compatibility issues across operating systems.
What About Android?
For Protobufs in Android, I use (yet another) Square library. Specifically, Wire. Wire is a method-count friendly implementation of Protocol Buffers, that comes with a code generator too (note, at this time, I haven’t tried Google’s proto3 JavaNano implementation - but Wire uses some of it already).
Unfortunately, all of the generated classes are marked ‘final’, so they’re not extendable… So, instead, I created a few static methods inside a WireUtils class to perform this length-delimited encoding and decoding.
public static void writeDelimitedTo(OutputStream outputStream, List<Message> messages) throws IOException {
for (Message message : messages) {
writeDelimitedTo(outputStream, message);
}
}
public static void writeDelimitedTo(OutputStream outputStream, Message message) throws IOException {
int size = message.adapter().encodedSize(message);
BufferedSink sink = Okio.buffer(Okio.sink(outputStream));
sink.writeIntLe(size);
message.encode(sink);
sink.emit();
}
public static <M extends Message> List<M> readDelimitedFrom(InputStream inputStream, ProtoAdapter<M> adapter) throws IOException {
List<M> messages = new ArrayList<>();
BufferedSource source = Okio.buffer(Okio.source(inputStream));
while (!source.exhausted()) {
int size = source.readIntLe();
byte[] bytes = source.readByteArray(size);
messages.add(adapter.decode(bytes));
}
return messages;
}
Sample App
I’ve written a small sample app on Github which will either add one random value, or add 10 random values, to a file. It will then close the file, and re-open it for reading, and then populate a graph based on the file data.
For (unoptimized) performance metrics using length-delimited encoding with 86400 samples using an incrementing ‘x’ from 0, and random 0-1000 for the ‘y’ - on a Samsung S4 Mini running Android 4.4.2:
Filesize = 900kB
Build messages and then outputStream to file = 2900ms
Read messages from file inputStream and re-serialize into list of objects = 2700ms
What’s interesting is that if you change the length-delimiter from an int to a byte, there isn’t much of an appreciable difference in read/write time - however, there is a significant difference in the size of the file. This is also a function of the sample message, which only contains around 8 bytes, so the 4 byte delimiter is easily 30% overhead. As the size of the messages increases, the length-delimiter overhead decreases, but you still maintain full extensibility.
Here is an example of the same test as above, using a 1-byte length delimiter:
Filesize = 650kB
Build messages and then outputStream to file = 2800ms
Read messages from file inputStream and re-serialize into list of objects = 2600ms
Next Steps - Embedded Systems
One of the next things I want to play around with is Flatbuffers (or Cap’n Proto).
They can be considered an evolution of Protocol Buffers, but they are not without their downsides - so I would rather call them an alternative to Protobufs. The upsides are that they are significantly faster to use at runtime, and they don’t require as much memory usage - however, they also take up more room on the wire/disk. Also, they are slightly more complicated to work with.
For my most recent use case, size of the file was more important, as I wasn’t time-bound, nor was I very memory-bound (given that it was a move away from JSON).
One application where I like using Protocol Buffers, and I’m excited to try out FlatBuffers or Cap’n Proto is for embedded systems.
Putting some framing around Protobufs is a great way to transfer data over USB, Bluetooth, or serial - since it adds a lot of flexibility to the interface and data model (which is such a pain in the embedded world). The reason I like a zero-allocation protocol for this is because of the very limited resources in most embedded processors (even at the expense of a bit more wire traffic).
Hopefully I’ll be writing about that later this year!
Feature Photo credit: ben_nuttall / Foter / CC BY-SA